- Hadoop(2.x)云计算生态系统
-
Hadoop2.x云计算体系介绍
- 0.1. PIG-大数据离线分析利器
- 1. Hadoop2特点
- 2. Hadoop2概述
- 3. Hadoop2安装部署
- 4. Kafka分布式消息队列
- 5. AerospikeDB实时数据库
- 6. PIG 大数据离线分析利器
- 7. zookeeper分布式管理
-
8.
Samza分布式流计算
- 8.1. 背景
- 8.2. 概念
- 8.3. 架构
- 8.4. 流处理系统对比
- 8.5. API
- 8.6. 容器 Container
-
8.7.
Jobs
- 8.7.1. JobRunner
- 8.7.2. Configuration
- 8.7.3. Packaging
- 8.7.4. YARN Jobs
- 8.7.5. Logging
- 8.7.6. Reprocessing
-
8.8.
YARN
- 8.8.1. Application Master
- 8.8.2. Isolation
- 8.9. 案例实践
- 9. Spark 分布式内存计算
- 10. Scala语言
架构
参考链接:http://samza.incubator.apache.org/learn/documentation/0.8/introduction/architecture.html
本篇紧接着概念篇,从宏观角度上看一下Samza实时计算服务的架构是什么样的?
Samza是由以下三层构成:
- 数据流层(A streaming layer)
- 执行层(An execution layer)
- 处理层(A progressing layer)
那Samza是依靠哪些技术完成以上三层的组合呢?如下图所示:
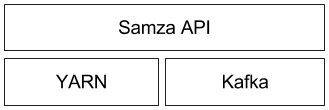
- 数据流:分布式消息中间件Kafka
- 执行:Hadoop资源调度管理系统YARN
- 处理: Samza API
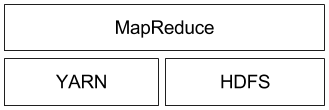
使用过大数据Hadoop的开发者可以类比下面的架构模式(存储由HDFS负责,执行层由YARN负责,而处理层则由MapReduce负责),如下图所示:
在你进一步了解这三层的每一部分前,应该要注意到对于Samza的支持并不局限于使用Kafka和YARN,具体需要根据你的业务场景来确定使用什么技术框架、工具作支持。特别是Samza的执行层和数据流层都是可插拔的,并且允许开发者自己去实现更好的替代品。
咱们深入一点,先介绍数据流层的解决方案——kafka(熟悉kafka的开发人员可以跳过)。
这个有着浓厚文艺气息名号的Kafka是一个分布式发布/订阅消息队列系统,它支持至少一次通信保障(即系统保证没有信息丢失,但是在某些故障情况下,消费者可能收到超过一条同样的信息)和高度可用的分区特性(即使一台机器宕机了,分区依然是可用的)。
对于Kafka来讲,每一条数据流被称为一个话题(topic)。每一个话题都在多台被称作broker的机器上进行分区和复制。当一个生产者发送一条消息给一个话题,它会提供一个key,这个key被用来决定这条消息应该被发送到哪一个分区。生产者发送信息而Kafka的broker则接收和存储它们。kafka的消费者能通过在一个话题的所有分区上订阅消息来读取消息。
值得补充的是,kafka有一些有趣的特点:
- 带着同一个key的所有消息都被划分到同一个分区,这就意味着如果你想要读到一个特定用户的所有消息,你只要从包含这个用户id的分区读取即可,而不是整个topic(假设把用户id用作key)
- 一个话题的分区是按顺序到达的一序列消息,所以你可以通过单调递增偏移量offset来引用任何消息(就好比放一个索引到一个数组里);这也意味着broker不需要跟踪被一个特定的消费者读取的消息,为什么呢?因为消费者保存了消息的偏移量offset能够跟踪到它。然后我们知道的是带着一个比当前偏移量小的消息是已经被处理过的,而每一个带着更大偏移量的消息还没有被处理过
再来看看新一代Hadoop推出的资源管理系统YARN
YARN(Yet Another Resource Negotiator)是新一代hadoop集群调度器。它可以让你在一个集群中配置一个容器,并且执行任意命令。当一个应用和YARN相互交互时,它看起来像这样的:
- Application:hi YARN Boy!我想用512MB内存在两台机器上跑命令X;
- YARN:cool, 你的代码在哪里?
- Application:代码在这里呢
- YARN:我正在网格node1 和node2上执行你的job。
Samza使用YARN去管理部署、容错、日志、资源隔离、安全以及本地化。这里提供一个简要介绍(见http://hortonworks.com/blog/apache-hadoop-yarn-background-and-an-overview/)。
YARN的架构
当然为了节省大家的时间,宏观上来看一下YARN的架构吧。首先YARN也是有三个层次构成:一个资源管理器(ResourceManager),,一个节点管理器(NodeManager)和一个应用管理器(ApplicationMaster)。在一个YARN网格里,每一台机器上都跑着一台NodeManager,它负责在所在的机器上启动进程。而一个ResourceManager则与所有的NodeMananger交互告诉它们跑什么应用,反过来NodeManager也会告诉ResourceManager它们希望什么时间在集群里跑这些东东。对于第三层ApplicationMaster则是让特定应用的代码跑在YARN集群上。它负责管理应用的负载、容器(通常是UNIX进程),并且当其中一个容器失败时发出通知。
Samza and YARN
Samza提供了一个YARN ApplicationMaster和一个开箱即用的YARN任务运行器。这样说大家可能觉得不直观,Samza和YARN的集成可以用下图来概述(不同的颜色表示不同的机器):
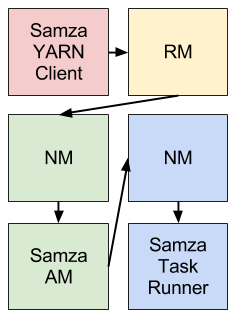
解释一下上面这个图吧,Samza的客户端当它想开始一个新job时会告诉YARN的RM(ResourceManager,以下简称RM)。这个RM会告诉YARN的一个NodeManager(简称NM)为Samza的ApplicationMaster(AM)在集群里分配空间。一旦NM分配了空间,就会启动这个Samza的AM。AM开始后,它会要求RM为了跑SamzaContainers需要更多的YARN的containers。而且RM会和NMs一起为containers分配空间。一旦空间被分配,NMs就会开启Samza containers。
Samza
简要介绍了一下YARN,接下来就是我们的焦点Samza。Samza通过使用YARN和Kafka提供一个阶段性的流处理和分区的框架。把它们三者放在一起的话大概就是这个样子了:
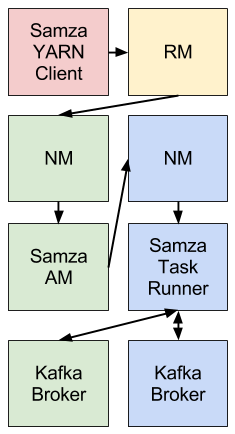
Samza的客户端使用YARN来运行一个Samza任务(job):YARN启动并且监控一个或者多个SamzaContainers,并且你的处理逻辑代码(使用the StreamTask API)在这些容器里运行。这些Samza 流任务的输入和输出都来自Kafka的Brokers(通常他们都是作为YARN NMs位于同台机器)
举个例子
比如我们想要统计页面访问数量。如果用SQL,你可能会写成下面这样的:
SELECT user_id, COUNT(*) FROM PageViewEvent GROUP BY user_id
尽管Samza目前不支持SQL,但是思路是相同的;计算这个需求需要两个任务:一个任务按照userid聚合消息,另一个任务则是计数。
进一步来说,第一个任务是分组工作通过发送带有相同userid的消息发送到一个中间话题的相同分区里,你可以通过使用第一个job发射的消息里的userid作为key来做到,并且这个key被映射到这个中间话题的分区(通常会取key对分区数目取余)。第二个任务处理中间话题产生的消息。在第二个任务里每个任务都会处理中间话题的一个分区。在对应分区中任务会针对每一个userid弄一个计数器,并且每次任务接受带着一个特定userid的消息时对应的计数器自增1。弄张图大家看看:
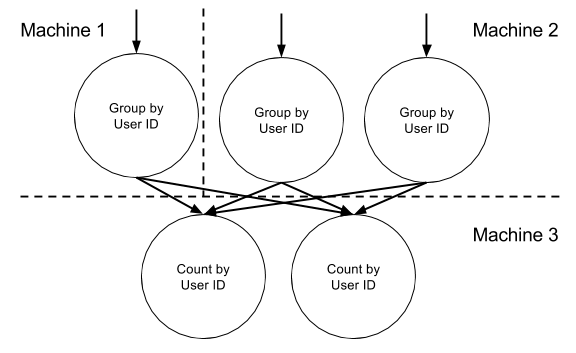
怎么样这个图是不是到处都看得到,和hadoop的Mapreduce的运行很相似对吧,每一个记录带着一个特定的key放到mapper里,被框架按照相同key进行分组,然后再reduce里进行计算统计。但是hadoop和Samza还是非常不同的,因为Hadoop的计算时基于一个固定的输入,而Samza则是和没有限定的数据流打交道。另外我自己再补充一条,流式计算框架和MapReduce另一个很大不同点在于mr的任务是会停止的,而Samza是持续不断处理。
Kafka接收到第一个job发送的消息并且把它们缓冲到硬盘,并且分布在多台机器上。这有助于系统的容错性提升:如果一台机器挂了,没有消息会被丢失,因为它们被存在其他机器里。并且如果第二个job因为某些原因消费消息的速度慢下来或者停止,第一个任务也没有影响:磁盘缓冲可以积累消息直到第二个任务快起来。
通过对topic的分区,将数据流处理拆解到任务中以及在多台机器上并行执行任务,使得Samza具有很高的消息吞吐量。通过结合YARN和Kafka,Samza实现了高容错:如果一个进程或者机器失败,它会自动在另一台机器上重启它并且继续从消息终端的地方开始处理,这些都是自动化的。