- Hadoop(2.x)云计算生态系统
-
Hadoop2.x云计算体系介绍
- 0.1. PIG-大数据离线分析利器
- 1. Hadoop2特点
- 2. Hadoop2概述
- 3. Hadoop2安装部署
- 4. Kafka分布式消息队列
- 5. AerospikeDB实时数据库
- 6. PIG 大数据离线分析利器
- 7. zookeeper分布式管理
-
8.
Samza分布式流计算
- 8.1. 背景
- 8.2. 概念
- 8.3. 架构
- 8.4. 流处理系统对比
- 8.5. API
- 8.6. 容器 Container
-
8.7.
Jobs
- 8.7.1. JobRunner
- 8.7.2. Configuration
- 8.7.3. Packaging
- 8.7.4. YARN Jobs
- 8.7.5. Logging
- 8.7.6. Reprocessing
-
8.8.
YARN
- 8.8.1. Application Master
- 8.8.2. Isolation
- 8.9. 案例实践
- 9. Spark 分布式内存计算
- 10. Scala语言
概念
参考链接:http://samza.incubator.apache.org/learn/documentation/0.8/introduction/concepts.html
希望上一篇背景篇让大家对流式计算有了宏观的认识,本篇根据官网是介绍概念,先让我们看看有哪些东西呢?
概念一:Streams
Samza是处理流的。流则是由一系列不可变的一种相似类型的消息组成。举个例子,一个流可能是在一个网站上的所有点击,或者更新到一个特定数据库表的更新操作,或者是被一个服务或者事件数据生成所有日志信息。消息能够被加到另一个流之后或者从一个流中读取。一个流能有多个消费者,并且从一个流中读取不会删除消息(使得消息能够被广播给所有消费者)。另外消息可以有一个关联的key用来做分区,这个将在后面说明。
Samza支持实现流抽取的可插拔系统:在kafka里,流是一个topic(话题),在数据库里我们可以通过消费从一个表里更新操作读取一个流;而在hadoop里我们可能跟踪在hdfs上的一个目录下的文件。
概念二:Jobs
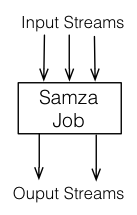
Samza的jobs 是对一组输入流设置附加值转化成输出流的程序(见下图)。为了扩展流处理器的吞吐量,我们将任务拆分更小的并行单元:分区Partitions和任务tasks
概念三:Partitions
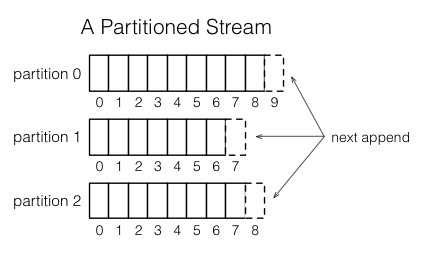
每个流都被分割成一个或多个分区,并且在流里的每一个分区都总是一个有序的消息序列。每个消息在这个序列里有一个被叫做offset(中文称它为偏移量),它在每一个分区里都是唯一的。这个偏移量可以是一个连续的整数、字节偏移量或者字符串,这取决于底层的系统实现了。
当有一个消息加入到流中,它只会追加到流的分区中的一个。这个消息通过写入者带着一个被选择的key分配到它对应的分区中。举个例子,如果用户id被用作key,那么所有和用户id相关的消息都应该追加到这个分区中。
概念四:Tasks
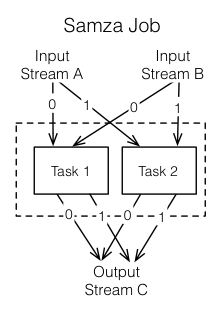
一个job通过把他分割成多个任务Task进行扩展。任务Task作为job的并行单元,就好比上述提到的流中的分区。每个任务Task为每个job输入流消费来自一个分区的数据。
按照消息的偏移,一个任务按序处理来自它的输入分区的消息。分区之间没有定义顺序,这就允许每一个任务独立执行。YARN调度器负责分发任务给一台机器,所以作为一个整体的工作job可以分配到多个机器并行执行。
在一个job中任务Task的数量是由输入分区决定的(也就是说任务数目不能超过分区数目,否则就会存在没有输入的任务)。可是,你能改变分配给job的计算资源(比如内存、cpu核数等)去满足job的需要,可以参考下面关于container的介绍。
另外一个值得注意的是分配给task的分区的任务绝不会改变:如果有一个任务在一台失效的机器上,这个task会被在其它地方重启,仍然会消费同一个流的分区。
概念五:Dataflow Graphs
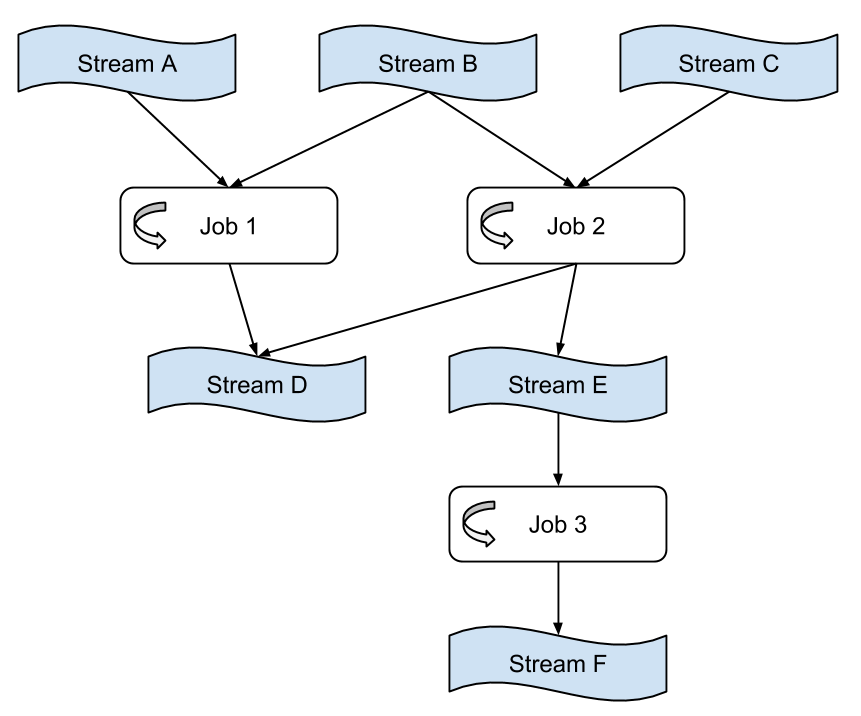
我们能组合多个jobs去创建一个数据流图,其中节点表示包含数据的流,而边则是进行数据传输。这个组合纯粹是通过jobs作为输入和输出的流来完成。这些jobs也是解耦的:他们不需要基于相同的代码库,并且添加、删除或者重启一个下游任务不会影响上游的任务。
概念六: Containers
分区Partitions和任务tasks都是并行的逻辑单元——他们不会与特定的计算资源(cpu、内存、硬盘等)的分配相符合。Containers则是物理的并行单元,并且一个容器本质上是一个Unix进程。每个容器跑着一个或多个tasks。tasks的数量是从输入的分区数自动确定和固定下来的,但是容器的数量(cpu、内存资源)是在运行时用户设定的并且能在任何时刻改变。